|
|

|

|
| e-Pub |
Section: New Results
Generating Unsupervised Models for Online Long-Term Daily Living Activity Recognition
Participants : Farhood Negin, Serhan Coşar, Michal Koperski, François Brémond.
Keywords: Unsupervised Activity Recognition
Generating Unsupervised Models for Online Long-Term Daily Living Activity Recognition
In this work, we propose an unsupervised approach that offers a comprehensive representation of activities by modeling both global and body motion of people. Compared to existing supervised approaches, our approach automatically learns and recognizes activities in videos without user interaction. First, the system learns important regions in the scene by clustering trajectory points. Then, a sequence of primitive events is constructed by checking whether people are inside a region or moving between regions. This enables to represent the global movement of people and automatically split the video into clips. After that, using action descriptors [90] , we represent the actions occurring inside each region. Combining action descriptors with global motion statistics of primitive events, such as time duration, an activity model that represents both global and local action information is constructed. Since the video is automatically clipped , our approach performs online recognition of activities. The contributions of this work are twofolds: (i) generating unsupervised human activity models that obtains a comprehensive representation by combining global and body motion information, (ii) recognizing activities online and without requiring user interaction. Experimental results show that our approach increases the level of accuracy compared to existing approaches. Figure 25 illustrates the flow of the system.
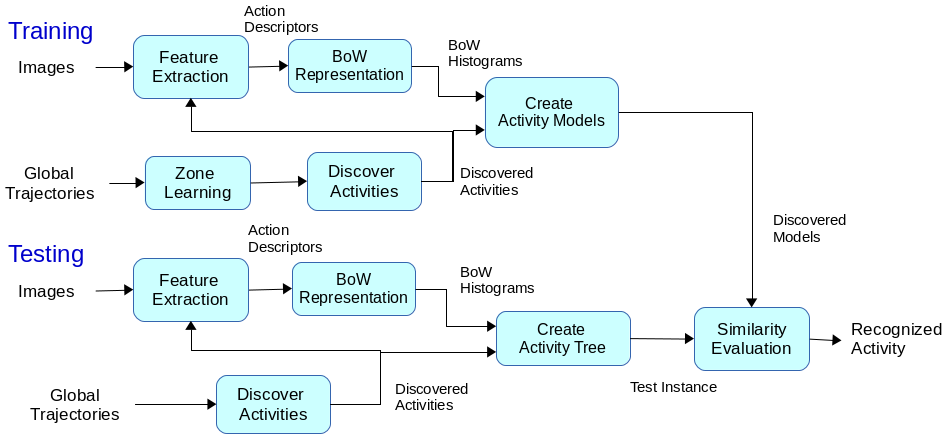
The performance of the proposed approach has been tested on the public GAADRD dataset [67] and CHU dataset (http://www.demcare.eu/results/datasets ) that are recorded under EU FP7 Dem@Care Project1 in a clinic in Thessaloniki, Greece and in Nice, France, respectively. The datasets contain people performing everyday activities in a hospital room. The activities considered in the datasets are listed in Table 1 and Table 2. Each person is recorded using RGBD camera of 640x480 pixels of resolution. The GAADRD dataset contains 25 videos and the CHU dataset contains 27 videos. Each video lasts approximately 10-15 minutes.
We have compared our approach with the results of the supervised approach in [90] . We did also a comparison with an online supervised approach that follows [90] . For doing this, we train the classifier on clipped videos and perform the testing using sliding window. In the online approach, a SVM is trained using the action descriptors extracted from groundtruth intervals. We have also tested different versions of our approach that i) only uses global motion features and ii) which only uses body motion features. We have randomly selected 3/5 of the videos in both datasets for learning the activity models. The codebook size is set to 4000 visual words for all the methods.
The performance of the online supervised approach and our approach in GAADRD dataset are presented in Table 1. In all approaches that use body motion features, HoG descriptors are selected since they give the best results. It can be clearly seen that, using models that represent both global and body motion features, our unsupervised approach enables to obtain high sensitivity and precision rates. Compared to the online version of [90] , thanks to the learned zones from positions and discovered activities, we obtain better activity localization, thereby better precision. However, since the online version of [90] utilizes only dense trajectories (not global motion), it fails to localize activities. Hence, it detects the intervals that does not include an activity (e.g. walking from radio desk to phone desk) and for ”prepare drug box“, ”watering plant“, and ”reading“ activities, it cannot detect the correct intervals of the activities. Compared to the unsupervised approach that either use global motion features or body motion features, we can see that, by combining both features, our approach achieves more discriminative and precise models, thereby improves both sensitivity and precision rates. By combining global and body motion features, our approach benefits from discriminative properties of both feature types. Table 1 also presents the results of the supervised approach in [90] . Although the supervised approach uses groundtruth intervals in test videos in an offline recognition scheme, it fails to achieve accurate recognition. As our approach learns the zones of activities, we discover the places where the activities occur, thereby we achieve precise and accurate recognition results. Since this information is missing in the supervised approach, it detects ”turning on radio“ while the person is inside drink zone preparing drink.
Table 2 shows the results of the online supervised approach and our approach in CHU dataset. MBH descriptor along y axis and HoG descriptor gives the best results for our approach and the online supervised approach, respectively. In this dataset, since people tend to perform activities in different places (e.g. preparing drink at phone desk), it is not easy to obtain high precision rates. However, compared to the online version of [90] , our approach detects all activities and achieves a much better precision rate. The online version of [90] again fails to detect activities accurately, thereby misses some of the ”preparing drink“ and ”reading“ activities and gives many false positives for all activities.
| Supervised | Online Version | Unsupervised | Unsupervised | Proposed Approach | ||||||
| Approach [90] | of [90] | (Only Global Motion) | (Only Body Motion) | |||||||
| ADLs | Sens. (%) | Prec. (%) | Sens. (%) | Prec. (%) | Sens. (%) | Prec. (%) | Sens. (%) | Prec. (%) | Sens. (%) | Prec. (%) |
| Answering Phone | 100 | 88 | 100 | 70 | 100 | 100 | 57 | 100 | 100 | 100 |
| Establish Acc. Bal. | 67 | 100 | 100 | 29 | 100 | 86 | 50 | 100 | 100 | 86.67 |
| Preparing Drink | 100 | 69 | 100 | 69 | 78 | 100 | 100 | 100 | 100 | 100 |
| Prepare Drug Box | 58.33 | 100 | 11 | 20 | 33.34 | 100 | 33.34 | 100 | 33.34 | 100 |
| Watering Plant | 54.54 | 100 | 0 | 0 | 44.45 | 57 | 33 | 100 | 44.45 | 100 |
| Reading | 100 | 100 | 88 | 37 | 100 | 100 | 38 | 100 | 100 | 100 |
| Turn On Radio | 60 | 86 | 100 | 75 | 89 | 89 | 44 | 100 | 89 | 100 |
| AVERAGE | 77.12 | 91.85 | 71.29 | 42.86 | 77.71 | 90.29 | 50.71 | 100 | 80.97 | 98.10 |
| Supervised Approach [90] | Online Version of [90] | Proposed Approach | ||||
| ADLs | Sens. (%) | Prec. (%) | Sens. (%) | Prec. (%) | Sens. (%) | Prec. (%) |
| Answering Phone | 57 | 78 | 100 | 86 | 100 | 65 |
| Preparing Drink | 78 | 73 | 92 | 43 | 100 | 58 |
| Prepare Drug Box | 100 | 83 | 100 | 43 | 100 | 100 |
| Reading | 35 | 100 | 92 | 36 | 100 | 78 |
| Using Bus Map | 90 | 90 | 100 | 50 | 100 | 47 |
| AVERAGE | 72.0 | 84.80 | 90.95 | 48.76 | 100 | 70.00 |
Thanks to the activity models learned in unsupervised way, we accurately perform online recognition. In addition, the zones learned in an unsupervised way help to model activities accurately, thereby most of the times our approach achieves more accurate recognition compared to supervised approaches. This paper has been published in third Asian Conference on Pattern Recognition (ACPR 2015) [35] .